


Human, All Too Human
Superintelligence requires learning things we can’t teach


Are we on the verge of an intelligence explosion?
OpenAI’s latest model, ChatGPT o3, just shattered performance records across the most challenging AI benchmarks. It outperforms 99.9% of human coders in competitive programming, achieves breakthrough results in frontier mathematics (25% vs 2% previous state-of-the-art), and scores 87.5% on the ARC challenge—a test specifically designed to measure an AI's ability to acquire new skills.
AI is fast approaching the capability of top human experts in many domains. Most researchers agree that we have not yet achieved AGI (Artificial General Intelligence), but it feels increasingly likely that AI will soon be performing most roles about as well as the best humans.
AGI implies AI as intelligent as a human across a wide range of tasks. Certainly, AI is already better than most humans at many things, but it still struggles with some things that are easy for most humans, and it still lags behind the best humans at most things.

Computers have long benefited from some advantages over humans - speed, scale, ruthless execution. Humans can’t compete with computers at large scale data analysis or high frequency trading or factoring large numbers. Those advantages are very real and very meaningful, but today we’re seeing something different: AI is mastering the creative, nuanced, intuitive tasks that were long considered uniquely human territory.
Beyond AGI, ASI (Artificial Super Intelligence) implies an intelligence that is clearly superior to humans in virtually all domains. No one of note believes that AI has already achieved ASI, but many believe that once AI is close to human-level intelligence, it will be able to improve itself much faster than humans alone, leading to an intelligence explosion. Some infer from the last few months of rapid progress that this singularity is already underway.
In Situational Awareness, Leopold Aschenbrenner points out that we don’t need AI to be able to do everything humans can do to create an intelligence explosion. AI just needs to do one thing: advance AI research about as well as humans can. Because once we have one AGI, we’ll have unlimited AGIs - “Rather than a few hundred researchers and engineers at a leading AI lab, we’d have more than 100,000x that—furiously working on algorithmic breakthroughs, day and night. Yes, recursive self-improvement, but no sci-fi required; they would need only to accelerate the existing trendlines of algorithmic progress.”
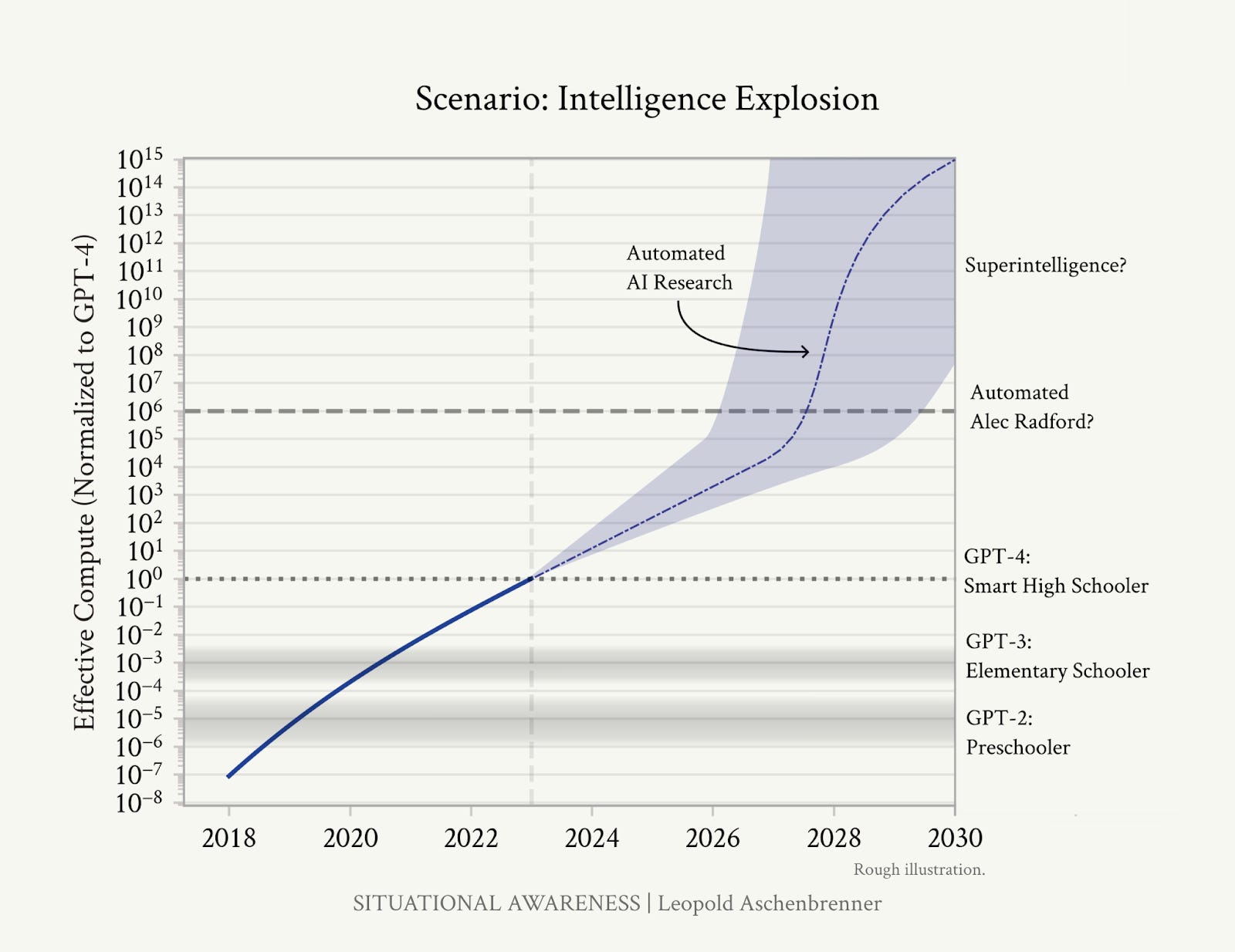
I do believe an intelligence explosion is imminent, but it will demand new training paradigms beyond scaling. We might be able to train human-level intelligence (AGI) by teaching AI everything we know, but superintelligence (ASI) requires learning things we don’t know.
Why? The human data bottleneck. As I’ve written about before, today’s models are trained almost entirely on human data and human feedback - predicting the next token in sequences we’ve produced, and rewarding responses favored by human users and labelers. As François Chollet points out in his announcement of o3’s ARC score, today’s models are “reliant on expert-labeled, human-generated CoT data” to learn.
These models will get better and better at mimicking the best and brightest among us. Models may even recombine known reasoning methods to uncover new breakthroughs, but they remain bound to known human reasoning patterns. AI trained on high-quality thinking from humans might learn to perfectly approximate, but never surpass, that level of thinking. AI cannot learn something fundamentally new or surpass the quality of its training data, if there is no ground-truth information entering the system outside of that training data.
So, what is missing? What do we need to achieve superintelligence?
One way to answer this question is to consider the few domains in which superintelligence has already been achieved.
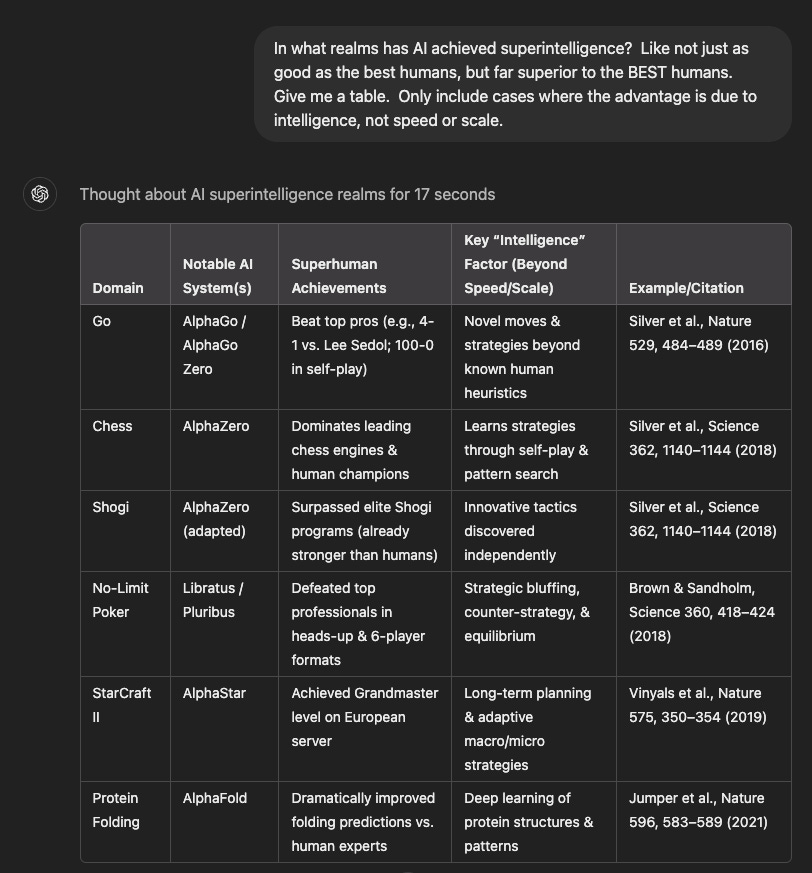
Lots of games, and protein folding.
In these domains, AI learned new things by exploring and testing novel strategies outside human data, using objective, ground-truth feedback.
AlphaGo, for example, learned by playing countless games against itself, using game outcomes to determine what works and what doesn’t. This gameplay introduced new ground truth information beyond the original human data - the actual outcome of simulated games. If the model had been trained only by human data and expert human labelers - deciding which move seemed better in any given situation - it could only ever learn to approximate, but never fundamentally surpass, human preferences for a good move. Self-play was also key for achieving superhuman performance in the other games.
For protein folding, ground truth came from experimentally determined observations, not game outcomes. AlphaFold learned from this data, and explored by generating new potential solutions, checking their plausibility against known physical and chemical constraints and iterating accordingly.
For AI to learn something fundamentally new - something it cannot be taught by humans - it requires exploration and ground-truth feedback.
Exploration: The ability to try new strategies, experiment with new ways of thinking, discover new patterns beyond those present in human-generated training data.
Ground-Truth Feedback: The ability to learn from the outcome of explorations. A way to tell if these new strategies - perhaps beyond what a human could recognize as correct - are effective in the real world.
This isn’t surprising. When we aren’t taught, humans learn new things from trial-and-error - optimizing new approaches against real-world outcomes. Human intelligence itself emerged from an evolutionary process of exploring novel genetic combinations and iterating on those that work. The real world is infinitely complex and scalable, so human learning and evolution never approach the limit of our training data.
Today’s leading models still rely on humans for feedback, limited to interpretations of reality that we recognize as correct. Achieving superhuman intelligence requires testing new strategies we aren’t qualified to judge. There are many ways we might achieve this, whether in physically embodied intelligence, complex simulations grounded in scientific constraints, or predicting real world outcomes.
Are AI agents - the latest buzzword - the solution here? Not exactly. AI agents freely interact with users and data to accomplish tasks, going beyond the limitations of a chat interface. These interactions will create new feedback channels to learn from based on the success or failure of those attempts. This creates a data flywheel - more tasks lead to more training data, leading to better performance, to increased adoption, and thus even more tasks. However, for now, most of this feedback is still a reflection of human knowledge - a thumbs up on a draft, a closed deal, a viral video. Most agents won’t be freely tackling problems with objective, real-world feedback, like designing rocket ships or testing novel therapeutics.
An intelligence that can perfectly predict and mimic humans is like a really smart human.
An intelligence that can perfectly predict outcomes in the real world would be a god.
True superintelligence demands exploration and feedback from the real world. Without it, AI remains a reflection of human knowledge, never transcending our limited understanding of reality.